Jump to
Stay tuned for
more insights
Follow us on
Pentesting User Interfaces: How to Phish Any Chrome, Outlook, or Thunderbird User
In this blog post, we demonstrate how graphical user interfaces could be vulnerable to spoofing attacks by using certain Unicode characters.
If you received this email, could you spot the malware?
Social engineering attacks can range from classical “Nigerian prince” scams to really sophisticated spear phishing techniques. In this blog post, we explore some application pentesting techniques and show how certain UI bugs could be exploited to fool even the most tech-savvy of users.
There is no doubt that every modern piece of software now utilizes graphical user interfaces in one way or another. GUI elements are often used to display some of the most critical pieces of information which we base our decisions on. Take the web browser you’re using right now to read this blog post for example – you trust that the address bar displays the true URL of the current webpage, don’t you? If it instead displayed the domain name of your bank, would you trust it?
Likewise, you trust that the sender address that your email client shows is the actual sender address of the emails you receive, and so you decide whether to trust the content of these emails or not based on that. After all, we now have email authentication technologies in place to prevent email spoofing such as SPF (Sender Policy Framework), DKIM (DomainKeys Identified Mail), and DMARC (Domain-based Message Authentication, Reporting & Conformance).
But what if these GUI components could be tricked into displaying fake information, wouldn’t we lose all trust in those programs to the point they become useless?
GUI elements do have inherent limitations which we can exploit. First, they are limited by your screen size, and they often have fixed width or height. And likely they expect data in a certain format or language to display.
Chrome Link Spoofing
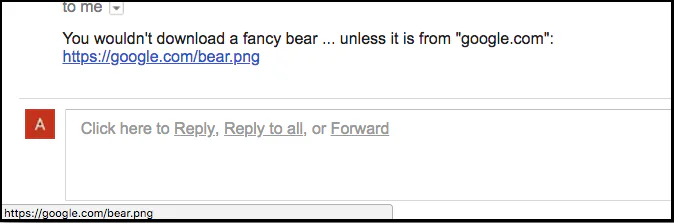
Let’s take some practical examples to illustrate our point. Imagine that you received a link in an email. When you hover over the link, you see “https://google.com/bear.png” as such:
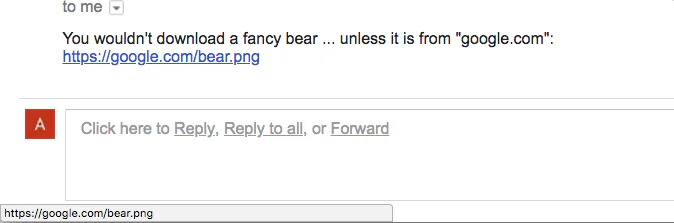
This does seem safe to click as it points to the official Google domain name (google.com) and leads to a harmless .png photo, right?
But it isn’t what it seems, this is the true link in HTML:
<a href="https://attacker.com/#


https://google.com/bear.png">https://google.com/bear.png</a>As you can see, the link actually points to “attacker.com” and not “google.com”. But because of the U+2028 (LINE SEPARATOR) Unicode character in the hash part of the URL (HTML-encoded as “ ”), the status bubble on the bottom left corner of the browser rendered the URL with new lines like this:
https://attacker.com/#
https://google.com/bear.pngAnd as the status bubble has fixed height, it failed to display the full multi-line URL, so the only part of the URL that got displayed was the bottom part “https://google.com/bear.png”.
Hiding Malicious Downloads
Clicking the link would cause a file named “bear.png” to get downloaded in Google Chrome’s download bar:

But the true file extension is “.pkg” and not “.png”. The full file name is actually “bear.png[U+2028][U+2028].pkg” where [U+2028] is the Unicode line separator character which gets rendered as a new line, causing the “.pkg” extension at the end of the file name to get rendered out of view.
In other words, this causes Chrome to render the file name as:
bear.png
.pkgThe second/third line obviously cannot fit on screen, giving us the ability to spoof any extension we want.
Now you might think that you still wouldn’t click a link or open any attachments from an untrusted source even if it points to a trusted domain name or looks like a harmless “.png” file. But what if the sender address could be spoofed as well for any domain name in spite of SPF/DKIM/DMARC/whatever?
Pentesting Email Clients
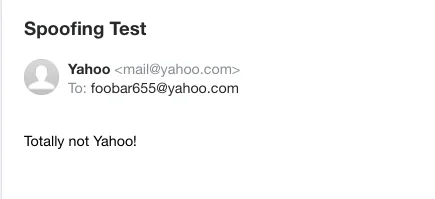
Take a look at the sender addresses in these emails:
Yahoo! Mail
Mozilla Thunderbird (CVE-2020-12397)

Microsoft Outlook

The sender address in all of these emails looks like it’s from a trusted domain name (e.g., microsoft.com), but that’s not really the case. To help you understand what’s going on, let’s look at how most email clients display the ‘from’ address. Email clients typically display it in this format:
Foo Bar <foobar@emailservice.com>This can be broken down to two parts: the display name “Foo Bar” and the sender address “foobar@emailservice.com” enclosed in angle brackets.
But what happens if we set the value of the display name to something like this instead:
Microsoft <mail@microsoft.com> [...lots and lots of whitespace characters].The answer is what you see in the screenshots above. The trick is simply that we are padding the display name with too many Unicode ideographic spaces (U+3000) so that the actual sender address gets rendered out of view while a fake sender address is used at the beginning of the display name (e.g., “Microsoft mail@microsoft.com“) to make it look like the email came from a trusted source. The full ‘from’ address actually looks like this:
Microsoft <mail@microsoft.com> [...lots and lots of whitespace characters]<attacker@attacker.com>But because of the extraneous whitespaces in the display name, the attacker@attacker.com part (that is, the sender address) gets rendered out of view and you only get to see the part at the beginning of the display name (that is, “Microsoft mail@microsoft.com“) which tricks you into thinking it’s the real sender address.
If you inspect the “From:” email header, it looks something like this:
From: =?UTF-8?B?TWljcm9zb2Z0IDxtYWlsQG1pY3Jvc29mdC5jb20+44CA44CA44CA44CA44CA?=
=?UTF-8?B?44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA?=
=?UTF-8?B?44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA?=
=?UTF-8?B?44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA?=
=?UTF-8?B?44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA?=
=?UTF-8?B?44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA44CA44CALg==?=
<attacker@attacker.com>But who actually inspects the headers of every email they receive? Life surely is too short for that.
Now you see that links, filenames, and sender addresses can all be easily spoofed. But what about the domain name in your browser’s URL bar? Can it be spoofed as easily too?
Exploiting RTL / LTR domains (Chrome CVE-2018-18348)
Let’s take CVE-2018-18348 as an example (this is the most recent URL spoofing vulnerability we discovered):

This screenshot is from Chrome for Android, it clearly shows the domain name as “www.google.com”. But the actual domain name is “www.google.com.مثال.السعودية”. To help you understand what’s going on, this is the order which the full URL is displayed in:

In case you’re not aware, this is called a multilingual bidirectional domain name which contains characters from two different character sets, and as such, it’s displayed with different display orders (from right to left and from left to right). The “www.google.com” part is only the subdomain of an internationalized domain name “مثال.السعودية”. And the “٠” character in the pathname is the Unicode character U+0660 (Arabic-Indic Digit Zero).
The browser is supposed to display RTL domain names like “مثال.السعودية” from right to left, and LTR domain names like “www.google.com” from left to right. If the domain name is too long like “subdomain.subdomain.subdomain.example.com”, the browser is supposed to elide the domain name from the left so that “example.com” is always displayed to the user (that is, the top- and second-level domain names).
But when RTL and LTR domain names are mixed together (e.g., “www.google.com.مثال.السعودية/٠”), the browser doesn’t properly display the RTL SLD/TLD “مثال.السعودية”, and it gets rendered out of view. This results in the subdomain(s) “www.google.com” being displayed to the user as if it were the actual domain name.
This might remind you of a known class of attacks called “visual spoofing” where lookalike Unicode characters (called “homoglyphs”) are used to spoof domain names and such—however, UI tricks like the above extend what you can do as an attacker/red teamer and help in bypassing existing countermeasures like how web browsers display IDN domain names in punycode to defend against spoofing….
As part of responsible disclosure, we’ve reported these UI bugs to the affected software vendors, and the bugs have (mostly) been fixed since then. But the same techniques could be applicable against GUI components of any web or native application where Unicode is supported in user input.
In conclusion, building secure software surely is hard as new attacks keep evolving by the day. And software vendors are often overwhelmed trying to keep pace with these attacks. So at the end of the day, it all comes down to user awareness in order to stay secure online.
References:
- Right-to-Left Scripts for Internationalized Domain Names for Applications (IDNA): https://tools.ietf.org/html/rfc5893
- https://nvd.nist.gov/vuln/detail/CVE-2020-12397
- https://nvd.nist.gov/vuln/detail/CVE-2018-18348